
Molly Lewis
[mollyllewis@gmail.com]Publications • LinkedIn • CV • GitHub
About me
I'm a computational social scientist interested in human learning and language. I use a wide range of methods including behavioral experiments, NLP techniques, and analysis of large trace data. Currently, I'm a Quantitative Researcher at Meta.
I earned my PhD in Psychology from Stanford University where I worked with Michael C. Frank. I was then a post-doctoral scholar with James Evans (University of Chicago) and Gary Lupyan (UW-Madison). Before graduate school, I studied linguistics at Reed College. I have authored 20+ articles in peer-reviewed journals, including Nature Human Behavior, PNAS, and Psychological Science. My work has been featured in Scientific American, Fast Company, and The Kansas City Star.
Recent work
Cross-linguistic variability in meaning
I'm interested in the ways in which representations of meaning vary across groups of people. In one project (Lewis, Cahill, Madnani, & Evans, PNAS, 2023), we've examined this question through word embedding models trained on second-language text. A key finding from this work is that languages vary more in terms of their "global" semantic relations, relative to "local" ones.
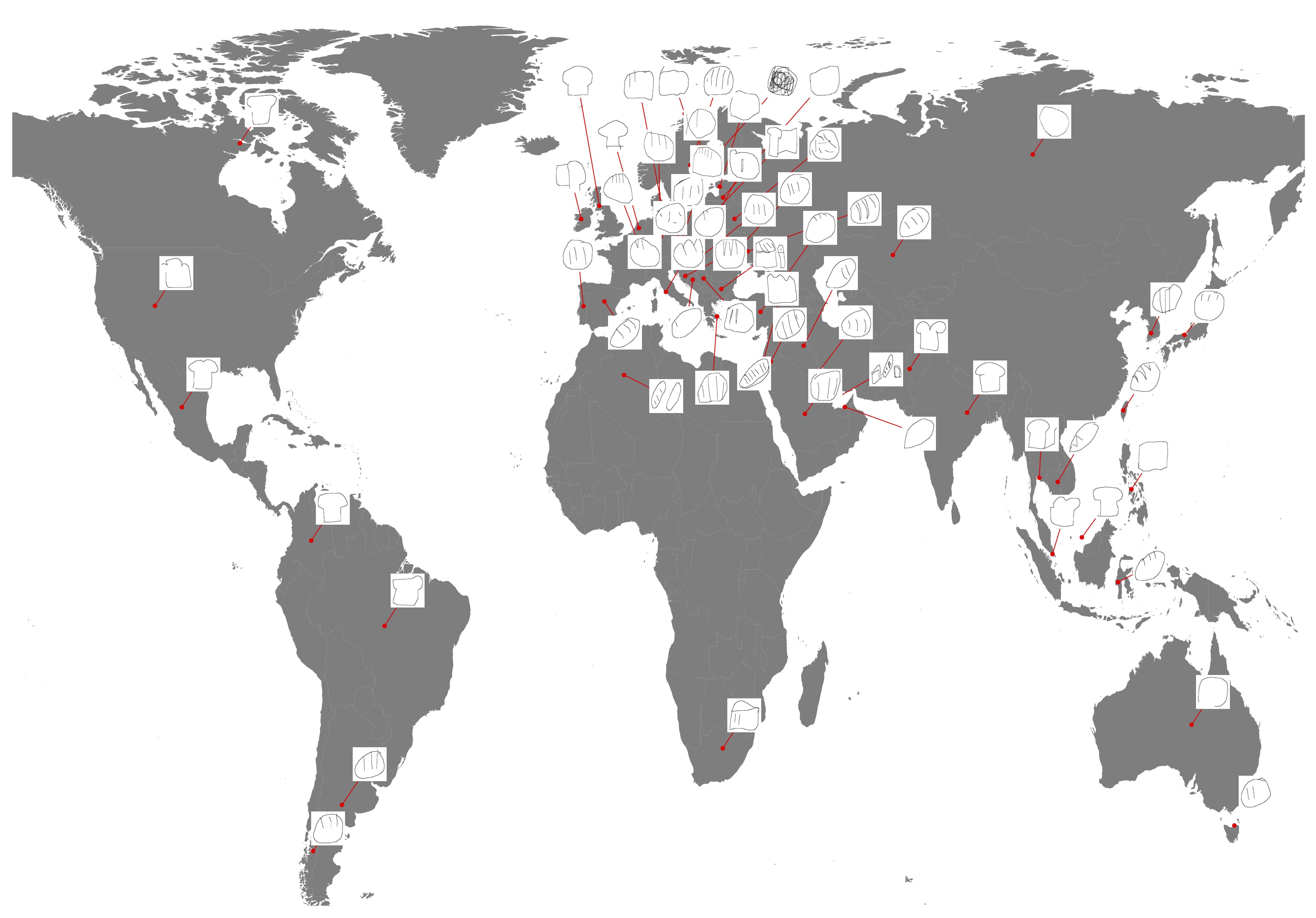
In a related project, we've analyzed millions of sketches from the Google QuickDraw dataset. The plot below shows the prototypical “bread” in each country, calculated as the drawing with the smallest average pairwise distance to other drawings from the same country (Lewis, Balamurugan, Zheng, & Lupyan, 2021) .
Gender bias in language models
In several papers, I've examined the extent to which word co-occurrence statistics in language corpora contain subtle information about gender stereotypes, and how humans might learn this information. Here's a recent blog post on why the field of Responsible AI needs Psychology.
In Lewis and Lupyan (NHB, 2020), we measured how strongly people who spoke different languages held a particular gender stereotype (woman as associated with home life; men with careers), and then measured the strength of that stereotype in the co-occurrence statistics of the language they spoke. We found a strong correspondence between the two: people who speak languages that strongly encode this stereotype, tend to have speakers that also strongly encoded this stereotype. You can see slides from a presentation of this work above.

In Lewis, et al. (2021, Psych. Science), we examined how gender was represented in a corpus of popular children's books (e.g., Curious George, Pat the Bunny).
Teaching
At Carnegie Mellon University, I taught an R-based research methods course, Modern Research Methods. The course is designed to provide students with an understanding of the process of cumulative science, and to introduce them to a set of modern tools for conducting science in this framework. All the materials are open source.
Other
I love exploring found data, visualizing complex datasets, and making interactive dashboards. When not playing with data, I enjoy backpacking and baking pie 🍰
Theme by orderedlist